
这是一篇来源于阿里内部技术论坛的文章,原文在阿里内部获得一致好评。作者已经把这篇文章开放到云栖社区中供外网访问。文章内容做了部分删减,主要删减掉了其中只有阿里内部才能使用的工具的介绍,并删减掉部分只有通过阿里内网才能访问到的链接。
前言
平时的工作中经常碰到很多疑难问题的处理,在解决问题的同时,有一些工具起到了相当大的作用,在此书写下来,一是作为笔记,可以让自己后续忘记了可快速翻阅,二是分享,希望看到此文的同学们可以拿出自己日常觉得帮助很大的工具,大家一起进步。
闲话不多说,开搞。
Linux命令类
tail
最常用的tail -f
- tail -300f shopbase.log #倒数300行并进入实时监听文件写入模式
grep
- grep forest f.txt #文件查找
- grep forest f.txt cpf.txt #多文件查找
- grep 'log' /home/admin -r -n #目录下查找所有符合关键字的文件
- cat f.txt | grep -i shopbase
- grep 'shopbase' /home/admin -r -n --include *.{vm,java} #指定文件后缀
- grep 'shopbase' /home/admin -r -n --exclude *.{vm,java} #反匹配
- seq 10 | grep 5 -A 3 #上匹配
- seq 10 | grep 5 -B 3 #下匹配
- seq 10 | grep 5 -C 3 #上下匹配,平时用这个就妥了
- cat f.txt | grep -c 'SHOPBASE'
awk
1 、基础命令
- awk '{print $4,$6}' f.txt
- awk '{print NR,$0}' f.txt cpf.txt
- awk '{print FNR,$0}' f.txt cpf.txt
- awk '{print FNR,FILENAME,$0}' f.txt cpf.txt
- awk '{print FILENAME,"NR="NR,"FNR="FNR,"$"NF"="$NF}' f.txt cpf.txt
- echo 1:2:3:4 | awk -F: '{print $1,$2,$3,$4}'
2 、匹配
- awk '/ldb/ {print}' f.txt #匹配ldb
- awk '!/ldb/ {print}' f.txt #不匹配ldb
- awk '/ldb/ && /LISTEN/ {print}' f.txt #匹配ldb和LISTEN
- awk '$5 ~ /ldb/ {print}' f.txt #第五列匹配ldb
3 、 内建变量
NR:NR表示从awk开始执行后,按照记录分隔符读取的数据次数,默认的记录分隔符为换行符,因此默认的就是读取的数据行数,NR可以理解为Number of Record的缩写。
FNR:在awk处理多个输入文件的时候,在处理完第一个文件后,NR并不会从1开始,而是继续累加,因此就出现了FNR,每当处理一个新文件的时候,FNR就从1开始计数,FNR可以理解为File Number of Record。
NF: NF表示目前的记录被分割的字段的数目,NF可以理解为Number of Field。
find
- sudo -u admin find /home/admin /tmp /usr -name \*.log(多个目录去找)
- find . -iname \*.txt(大小写都匹配)
- find . -type d(当前目录下的所有子目录)
- find /usr -type l(当前目录下所有的符号链接)
- find /usr -type l -name "z*" -ls(符号链接的详细信息 eg:inode,目录)
- find /home/admin -size +250000k(超过250000k的文件,当然+改成-就是小于了)
- find /home/admin f -perm 777 -exec ls -l {} \; (按照权限查询文件)
- find /home/admin -atime -1 1天内访问过的文件
- find /home/admin -ctime -1 1天内状态改变过的文件
- find /home/admin -mtime -1 1天内修改过的文件
- find /home/admin -amin -1 1分钟内访问过的文件
- find /home/admin -cmin -1 1分钟内状态改变过的文件
- find /home/admin -mmin -1 1分钟内修改过的文件
pgm
批量查询vm-shopbase满足条件的日志
- pgm -A -f vm-shopbase 'cat /home/admin/shopbase/logs/shopbase.log.2017-01-17|grep 2069861630'
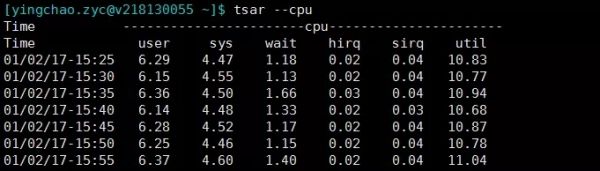
tsar
tsar是咱公司自己的采集工具。很好用, 将历史收集到的数据持久化在磁盘上,所以我们快速来查询历史的系统数据。当然实时的应用情况也是可以查询的啦。大部分机器上都有安装。
tsar ###可以查看最近一天的各项指标
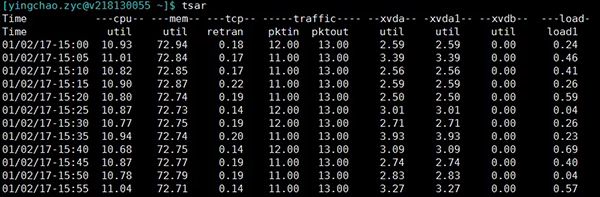
tsar --live ###可以查看实时指标,默认五秒一刷

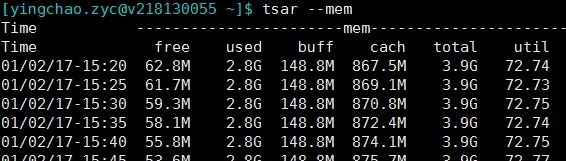
- tsar --mem
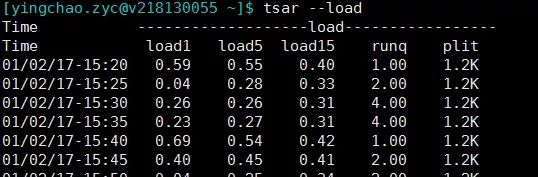
- tsar --load
- tsar --cpu
- ###当然这个也可以和-d参数配合来查询某天的单个指标的情况
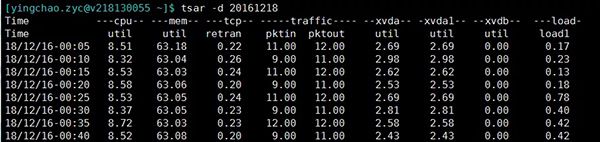
tsar --memtsar --loadtsar --cpu###当然这个也可以和-d参数配合来查询某天的单个指标的情况
top
top除了看一些基本信息之外,剩下的就是配合来查询vm的各种问题了
- ps -ef | grep java
- top -H -p pid
获得线程10进制转16进制后jstack去抓看这个线程到底在干啥
其他
- netstat -nat|awk '{print $6}'|sort|uniq -c|sort -rn #查看当前连接,注意close_wait偏高的情况,比如如下

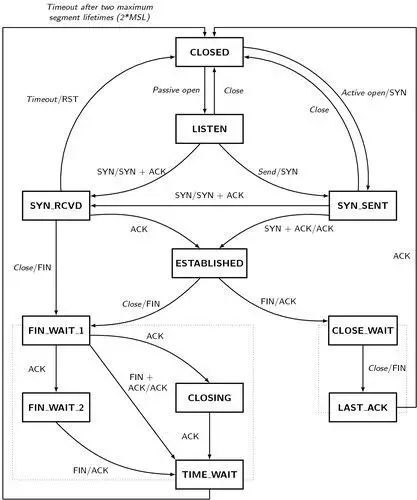
排查利器
btrace
首当其冲的要说的是btrace。真是生产环境&预发的排查问题大杀器。 简介什么的就不说了。直接上代码干
1、查看当前谁调用了ArrayList的add方法,同时只打印当前ArrayList的size大于500的线程调用栈
- @OnMethod(clazz = "java.util.ArrayList", method="add", location = @Location(value = Kind.CALL, clazz = "/.*/", method = "/.*/"))
- public static void m(@ProbeClassName String probeClass, @ProbeMethodName String probeMethod, @TargetInstance Object instance, @TargetMethodOrField String method) {
- if(getInt(field("java.util.ArrayList", "size"), instance) > 479){
- println("check who ArrayList.add method:" + probeClass + "#" + probeMethod + ", method:" + method + ", size:" + getInt(field("java.util.ArrayList", "size"), instance));
- jstack();
- println();
- println("===========================");
- println();
- }
- }
2、监控当前服务方法被调用时返回的值以及请求的参数
- @OnMethod(clazz = "com.taobao.sellerhome.transfer.biz.impl.C2CApplyerServiceImpl", method="nav", location = @Location(value = Kind.RETURN))
- public static void mt(long userId, int current, int relation, String check, String redirectUrl, @Return AnyType result) {
- println("parameter# userId:" + userId + ", current:" + current + ", relation:" + relation + ", check:" + check + ", redirectUrl:" + redirectUrl + ", result:" + result);
- }
更多内容,感兴趣的请移步:https://github.com/btraceio/btrace
注意:
- 经过观察,1.3.9的release输出不稳定,要多触发几次才能看到正确的结果
- 正则表达式匹配trace类时范围一定要控制,否则极有可能出现跑满CPU导致应用卡死的情况
- 由于是字节码注入的原理,想要应用恢复到正常情况,需要重启应用。
Greys
说几个挺棒的功能(部分功能和btrace重合):
<p style="padding: 0px 0px 15px; margin: 0px; color: rgb